

文章信息
收录期刊(分区):Bulletin of Engineering Geology and the Environment(2区)
论文题目:An integrated landslide susceptibility assessment in the Karakoram Mountains based on SBAS‑InSAR and machine learning: a case study of the Hunza Valley
论文作者:Xiaojun Su·Yi Zhang·Xingmin Meng· Mohib Ur Rehman· Dongxia Yue· Yan Zhao· Ziqiang Zhou·Fuyun Guo· Qiang Zhou · Baicheng Niu
论文地址:
https://link.springer.com/article/10.1007/s10064-025-04299-8
参考文献:Su X, Zhang Y, Meng X, et al. An integrated landslide susceptibility assessment in the Karakoram Mountains based on SBAS-InSAR and machine learning: a case study of the Hunza Valley[J]. Bulletin of Engineering Geology and the Environment, 2025, 84(6): 280.
一、文章写作框架
1 引言
2 研究区域
3 资料与方法
3.1 SBAS-InSAR和滑坡识别
3.2 变量
3.2.1地形因子
3.2.2与水文和森林覆盖有关的因素
3.2.3地质因素
3.2.4环境因素
4机器学习过程
4.1参数预处理
4.2候选机器学习模型选择
4.3模型拟合和调整
5结果
5.1滑坡清查
5.2基于SVC的滑坡易发性建模
5.3控制因素的重大性权重
6讨论
7结论
二、研究主要内容与结果、结论
山体滑坡在喀喇昆仑山脉范围广,灾害频发。本研究以巴基斯坦喀喇昆仑山脉西北部的罕萨河谷为例,该地区容易发生滑坡的聚集发展。基于2019-2020年的Sentinel-1A数据和2023年之前的几次实地调查,构建了更新的完整清单,包括53个SBAS InSAR检测到的活动滑坡和65个滑坡的光学图像解释。与地貌、水文、植被、地质、构造和环境相关的12个因素被纳入12个机器学习模型中的模型训练中:广义线性模型、Navies Bayes、最近邻、支持向量机等。
表1模型中使用的因素和字段缩写
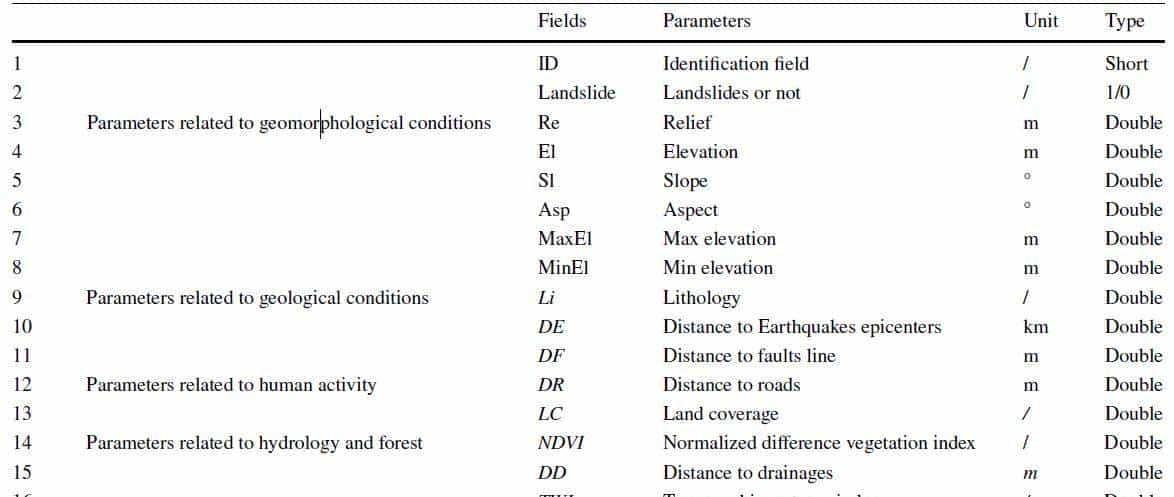
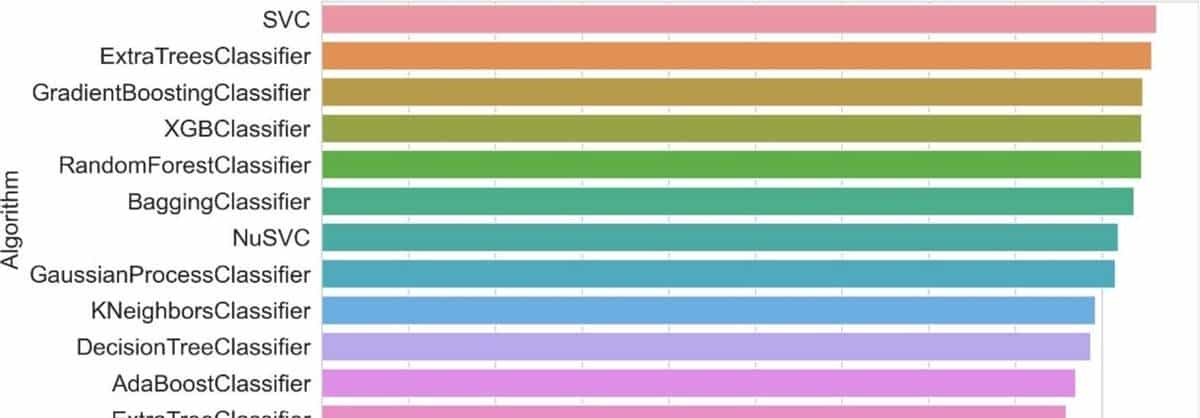
图1模型优化后ACC得分排名
通过超参数优化和模型预测的比较,确定了SVC的最佳性能,最大精度为0.96,十倍交叉验证的平均AUC为0.99,计算时间效率高(6.11秒)。这表明SVC是高海拔喀喇昆仑山脉滑坡易发性测绘的优化模型,特别是结合使用内部和外部因素以及InSAR在罕萨河谷检测到的滑坡。根据权重排序,地形(Re)、距震中距离(DE)、坡向(Asp)、岩性(Li)和距断层距离(DF)是影响滑坡易发性的主要因素;其次是平面曲率(PLC)、坡度(Sl)、NDVI、土地覆盖(LC)、剖面曲率(PFC)和排水距离(DD)。
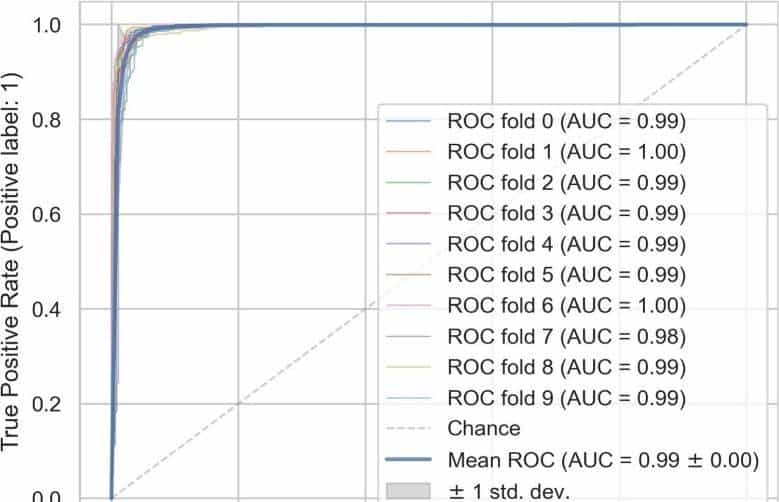
图2使用十倍交叉验证的SVC受试者工作特征曲线(ROC)和AUC
结果表明,滑坡易发程度中等的区域占62.14%,其次是高易发区(24.25%)。高滑坡易发性边坡主要位于罕萨河北侧,由于地形起伏较大,坡向较高,距离震中较近,距离断层较近。
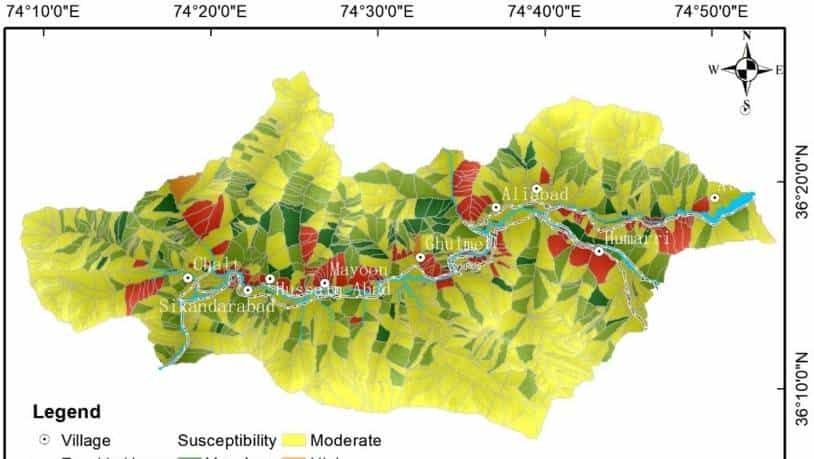
图3罕萨河谷滑坡易发性测绘结果
这项研究表明,地形和构造活动,如地形、坡向、地震和断层运动,对喀喇昆仑山脉罕萨的滑坡形成和发展做出了巨大贡献,是了解和促进罕萨山谷灾害管理和风险降低的关键一步。建模结果与识别滑坡的比较表明,SBASInSAR和机器学习相结合的更新方法是一种快速滑坡易发性测绘的有效方法,与传统方法相比具有更大的潜力,并且可以简单地清点旧滑坡。
三、文章创新点
这篇论文将机器学习和SBAS InSAR相结合,以巴基斯坦北部喀喇昆仑山脉的罕萨河谷为例,进行了滑坡易发性测绘研究。开发了一种结合SBAS InSAR监测变形和机器学习模型的程序,并利用一系列因果和指示因素进行了滑坡易发性评估。该研究的两个主要组成部分如下:(i)SBAS InSAR成功应用于滑坡识别,并通过提供滑坡样本应用于滑坡易发性评估。(ii)从22个机器学习模型中选择了12个来优化滑坡易发性概率的计算。
四、技术方法
4.1 XGBoost
XGBoost(eXtreme Gradient Boosting)是一种基于梯度提升框架的高效机器学习算法,它通过集成多棵决策树构建强劲的预测模型,在分类、回归、排序等任务中表现出色,尤其适合处理大规模数据集和高维特征。
应用场景:
金融风控:
预测用户违约风险:基于信用数据、交易记录等特征,构建XGBoost模型辅助信贷决策。反欺诈检测:识别异常交易行为(如频繁大额转账、异地登录),降低金融风险。
广告推荐:
精准推荐广告:根据用户浏览历史、兴趣爱好等信息,预测用户对广告的点击概率,提升转化率。排序优化:在搜索引擎或推荐系统中,学习有效的排序模型,提高内容曝光质量。
医疗诊断
疾病预测:依据患者症状、检查报告等数据,辅助医生进行疾病诊断(如糖尿病、癌症风险评估)。医疗影像分析:结合深度学习模型,对X光、CT等影像进行分类或分割,提高诊断准确性。
自然语言处理
文本分类:对新闻、评论等文本进行情感分析、主题分类。信息检索:优化搜索排名,提升用户检索体验。
4.2 RF
随机森林(Random Forest,RF)是一种基于集成学习思想的监督学习算法,通过构建多个决策树并结合它们的预测结果来提升模型的准确性和鲁棒性。它属于Bagging(Bootstrap Aggregating)类算法的典型代表,尤其擅长处理分类和回归问题,且对高维数据、噪声数据和非线性关系有较好的适应性。
应用场景:
分类问题:如客户流失预测、疾病诊断、图像分类。回归问题:如房价预测、股票价格预测。特征选择:通过特征重大性排名筛选关键特征。异常检测:识别与多数样本差异显著的异常点。
随机森林通过集成多棵决策树,结合Bootstrap采样和随机特征选择,实现了高准确性、强鲁棒性的预测模型。它适用于多种数据类型和任务,且能提供特征重大性评估,是机器学习中应用最广泛的算法之一。在实际应用中,需根据数据规模和问题复杂度调整参数,以平衡模型性能和计算效率。
4.3 Ensemble Methods
集成方法(Ensemble Methods) 是一种通过组合多个基学习器(Base Learners)来提升模型整体性能的机器学习技术。其核心思想是“三个臭皮匠,赛过诸葛亮”——通过汇聚多个模型的预测结果,减少单一模型的偏差或方差,从而获得更鲁棒、更准确的预测。
应用场景:
分类问题:如图像识别、文本分类(Bagging/Boosting)。回归问题:如房价预测、股票价格预测(Gradient Boosting)。特征选择:通过集成方法识别重大特征(如随机森林的特征重大性)。异常检测:结合多个模型的预测差异识别异常点。
集成方法通过“团结力量大”的策略,显著提升了机器学习模型的性能,成为解决复杂问题的利器。实际应用中需根据数据规模、特征类型和计算资源选择合适的方法。
4.4 高斯过程
高斯过程(Gaussian Processes, GP) 是一种强劲的非参数贝叶斯方法,用于回归、分类和时间序列预测等任务。它通过定义一个在函数空间上的先验分布,并结合观测数据更新后验分布,从而实现对未知函数的概率性建模。
经典案例:
机器人控制:通过高斯过程建模机器人动力学,实现安全探索。药物发现:预测分子活性,指导实验设计。气候建模:对气温、降水等环境变量进行空间插值。
高斯过程通过概率性建模函数空间,提供了灵活且强劲的非参数回归方法。尽管计算成本较高,但其对不确定性的自然处理使其在安全关键场景中具有独特优势。随着稀疏近似和深度扩展的发展,高斯过程正逐步拓展至更大规模的数据和更复杂的任务。
4.5 广义线性模型
广义线性模型(Generalized Linear Models, GLM) 是经典线性模型的扩展,通过引入链接函数(Link Function)和指数族分布(Exponential Family Distribution),能够处理非正态分布的响应变量(如二分类、计数、泊松等数据)。
应用场景:
医学统计:逻辑回归用于疾病风险预测(如糖尿病、心脏病)。泊松回归用于分析发病率与暴露因素的关系。社会科学:分析调查数据中的二分类或计数响应(如投票行为、犯罪率)。金融:伽马回归建模保险索赔金额。泊松回归预测交易次数。生态学:分析物种丰富度与环境变量的关系。
广义线性模型通过指数族分布和链接函数,将线性模型的适用范围扩展到非正态响应变量,成为统计学和机器学习中处理分类、计数等问题的标准工具。其灵活性、可解释性和计算效率使其在医学、金融、社会科学等领域广泛应用。结合正则化或非线性扩展(如GAM),GLM可进一步适应复杂数据场景。
4.6 朴素贝叶斯
朴素贝叶斯(Naive Bayes) 是一类基于贝叶斯定理和特征条件独立假设的简单概率分类算法,因其高效性和易实现性,在文本分类、垃圾邮件检测、推荐系统等领域广泛应用。尽管“朴素”(Naive)假设特征间完全独立在现实中一般不成立,但该模型在实际中仍表现优异,尤其在高维稀疏数据(如文本)中效果突出。
应用场景:
文本分类:垃圾邮件检测(区分正常邮件和垃圾邮件)。情感分析(判断评论是正面还是负面)。主题分类(如新闻分类为体育、政治、科技等)。推荐系统:根据用户历史行为(如点击、购买)预测兴趣类别。医学诊断:根据症状预测疾病类型(需结合领域知识调整特征独立性假设)。实时预测:资源受限场景(如移动设备)下的快速分类。
朴素贝叶斯通过简洁的贝叶斯定理和独立性假设,实现了高效的概率分类。尽管其假设在现实中常不成立,但在文本分类等高维稀疏场景中表现优异,且计算速度快、可解释性强。结合平滑技术和变体模型(如多项式、伯努利),朴素贝叶斯成为机器学习中实用且经典的基线方法。
4.7 Nearest Neighbors
最近邻算法(Nearest Neighbors,简称KNN) 是一类基于实例学习(Instance-based Learning)的监督学习算法,其核心思想是通过测量样本之间的距离,直接利用训练数据中的“邻居”信息进行分类或回归预测。KNN因其简单直观、无需显式训练过程(惰性学习)和适应性强等特点,在分类、回归、推荐系统等领域广泛应用。
应用场景:
分类任务:图像分类(如手写数字识别MNIST)。医学诊断(根据症状预测疾病)。回归任务:房价预测(根据房屋特征预测价格)。时间序列预测(如股票价格)。推荐系统:用户-物品协同过滤(基于用户或物品的类似性推荐)。异常检测:检测离群点(如信用卡欺诈检测)。
KNN是一种简单而强劲的算法,其核心在于利用局部类似性进行预测。尽管存在计算复杂度高、对高维数据敏感等缺点,但通过特征工程、距离度量优化和加速算法,KNN仍能在许多场景中发挥重大作用。在实际应用中,需结合数据特点选择合适的k值、距离度量,并注意处理噪声和不平衡数据问题。
4.8 SVM
支持向量机(Support Vector Machine,SVM)是一种经典的监督学习算法,主要用于分类和回归任务,尤其在分类问题中表现突出。它通过寻找数据中的最优超平面(Hyperplane)来实现分类,核心思想是最大化不同类别之间的间隔(Margin),从而提升模型的泛化能力。
应用场景:
分类任务:如人脸识别、文本分类、生物信息学(基因分类)。回归任务:支持向量回归(SVR),通过最小化预测值与真实值的偏差来建模。异常检测:通过定义“正常”数据的边界,检测偏离边界的异常点。
SVM是一种强劲的机器学习算法,尤其适合小样本、高维或非线性数据。其核心思想通过最大化间隔提升泛化能力,核技巧使其能处理复杂数据分布。尽管计算复杂度较高,但在许多领域(如计算机视觉、自然语言处理)仍被广泛应用。实际应用中需根据数据特点选择合适的核函数和参数。
4.9 Trees
树分类器(Tree Classifier) 是一类基于树结构的监督学习算法,通过递归地将数据空间划分为多个子区域,构建决策树(Decision Tree)或其扩展模型(如随机森林、梯度提升树等),用于分类任务。其核心思想是利用特征的分层决策规则,将复杂问题分解为一系列简单判断,最终实现高效分类。树分类器因其可解释性强、无需特征缩放、能处理混合类型数据等优点,广泛应用于金融风控、医疗诊断、推荐系统等领域。
应用场景:
金融风控:信用评分(根据收入、负债、历史记录等判断贷款风险)。医疗诊断:疾病预测(如根据症状、体检指标分类患者类型)。客户细分:用户画像(如根据行为数据划分高价值/低价值客户)。推荐系统:内容推荐(如根据用户兴趣和物品特征匹配推荐结果)。异常检测:识别异常交易(如信用卡欺诈检测)。
树分类器通过分层决策规则实现高效分类,单棵决策树适合小规模数据或需要可解释性的场景,而集成方法(如随机森林、梯度提升树)通过组合多棵树提升性能,适合大规模复杂数据。实际应用中,需根据数据规模、特征类型和任务需求选择合适模型,并通过调参(如树深度、子采样比例)优化性能。对于高维稀疏数据(如文本),可结合特征选择或降维技术进一步改善。
4.10 Discriminant Analysis
判别分析(Discriminant Analysis, DA) 是一类经典的监督学习方法,旨在通过建模不同类别数据的分布特征,找到一个或多个判别函数(Discriminant Functions),将样本划分到预定义的类别中。其核心思想是最大化类间差异(Between-class Variability)同时最小化类内差异(Within-class Variability),从而构建高效的分类边界。判别分析广泛应用于模式识别、生物统计、金融风控等领域,尤其适合处理多类别分类问题。
应用场景:
生物统计:基因表达数据分类(如癌症亚型识别)。金融风控:信用评分(区分高风险/低风险客户)。计算机视觉:人脸识别(Fisherface方法结合LDA和PCA)。文本分类:新闻主题分类(基于词频特征)。工业检测:产品缺陷检测(区分合格/不合格品)。
五、文章带来的思考
小编思考:这篇论文基于SBAS-InSAR和机器学习对以罕萨河谷为例喀喇昆仑山脉滑坡易发性综合评估。第一,小编认为可以学习这篇论文中所用的方法,将其应用于地面塌陷或沉降分析、亦或是特大型滑坡的评价等多方面,作为创新点开展相关研究。这篇论文在方法、结构上较为传统,其研究创新可能主要是其采用了遥感手段并结合了多种方法展开对比分析,工作量充足,且研究区研究较为少见。
预祝大家在未来寻找到自己的创新点,早日有更深层次研究成果和论文高中。
免责声明:本文内容是在本人自我解读和人工智能辅助下创作,由于小编本人的理解分析能力有限,其中的观点仅代表本人个人解读,仅供参考,如有分歧或遗漏之处,我们深表歉意。论文的版权归原期刊或出版方所有,本账号不提供论文全文的下载服务。若发现版权侵权请及时联系我们,我们将迅速处理。第三方转载时,不得更改内容且需要标注来源。对于第三方内容表述的准确性或合法转载性,本账号不承担责任。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...





