想知道如何让 AI 像图书管理员一样高效?老白将在本文中,深入浅出地讲解了 RAG 的核心原理,包括嵌入、类似性计算和生成技术,协助你快速掌握这项强劲的 AI 技术。
什么是 RAG?
想象一下,我们有一个超级机智的助手(就是 AI),但这个助手只知道它训练时学到的知识。如果我们想让它回答关于你自己文档的问题,它就需要先”阅读”这些文档。RAG(检索增强生成) 就是让 AI 能够先从我们的文档中找到相关内容,然后再生成回答的技术。
简单来说,RAG 的工作流程就像是:
- 把你的文档切成小段
- 把每段文字转换成”数字指纹”(嵌入)
- 当有人提问时,找到最相关的段落
- 把这些段落交给 AI,让它生成回答

什么是嵌入?
用生活中的例子理解
想象我们要整理一个巨大的图书馆。如果只是随意放书,找书会很难。但如果我们按照”主题”来分类——把所有烹饪书放在一起,所有科幻小说放在一起——找书就容易多了。
嵌入就是给文字做类似的分类,但更准确。它把每段文字转换成一串数字(向量),这串数字就像是文字的”指纹”或”坐标”。意思相近的文字,它们的”指纹”也会很类似。
列如说:
- “开心” 和 “快乐” 的指纹会超级接近
- “开心” 和 “悲伤” 的指纹会相距很远
简单的例子
假设我们只用两个数字来表明单词(实际上会用几百个数字):
# 用两个数字表明每个词的"位置"
king = [0.25, 0.75] # 国王
queen = [0.23, 0.77] # 王后
man = [0.15, 0.80] # 男人
woman = [0.13, 0.82] # 女人
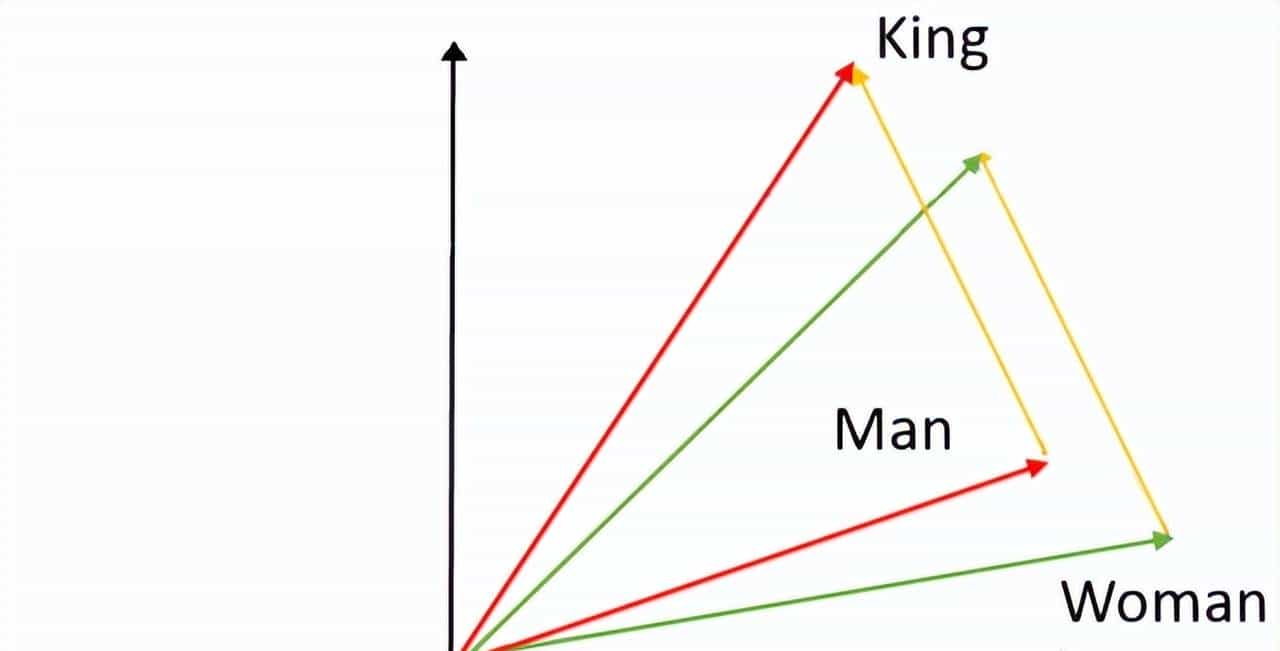
有趣的是,这些数字保留了词语之间的关系:
# 国王 - 男人 + 女人 = ?
king - man + woman
= [0.25, 0.75] - [0.15, 0.80] + [0.13, 0.82]
= [0.23, 0.77]
≈ queen # 结果接近"王后"!
这说明嵌入能够捕捉到词语之间的关系!
可视化理解
我们可以把这些词放到一个坐标系里看看它们的位置:
实际的嵌入更复杂
上面的例子只用了 2 个维度,但实际的嵌入模型会用 几百甚至上千个维度!列如:
- Word2Vec 使用 300 维
- BERT 使用 768 维
更多的维度意味着能够捕捉更丰富的语义信息。
如何判断两段文字有多类似?
余弦类似度:看两个箭头的”夹角”
当我们有了文字的”数字指纹”后,就可以用数学方法计算它们有多类似。最常用的方法是余弦类似度。
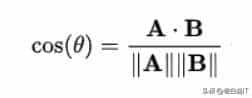
想象两支箭从同一点出发,指向不同方向:
- 如果两支箭指向几乎一样的方向(夹角很小),它们很类似
- 如果两支箭指向相反的方向(夹角很大),它们很不类似

其他计算方法
除了余弦类似度,还有:
- 欧几里得距离:直接测量两点之间的直线距离,距离越小越类似
- 点积:另一种数学计算方法,需要先把向量标准化
RAG 如何找到最相关的内容?
第一步:计算类似度
当用户提出问题时,RAG 系统会:
- 把用户的问题也转换成嵌入
- 计算这个问题和每一段文档的类似度
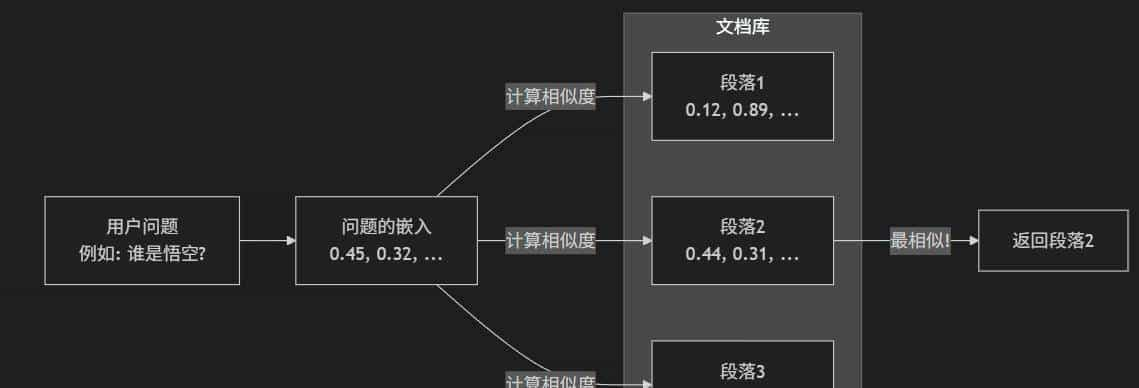
第二步:选择最相关的 k 个段落
系统会按类似度排序,然后选择最类似的几个段落(一般是 2-10 个),这就是所谓的 Top-k 检索。
加速搜索:近似最近邻(ANN)
当文档许多时,逐一比较太慢了。近似最近邻搜索是一种机智的方法,它不追求100%准确,但能快许多,而且结果一般也足够好。
实际代码演示
下面是一个简单的 RAG 系统示例代码:
from openai import AzureOpenAI
import os
from langchain_community.document_loaders import TextLoader
from langchain_openai import AzureOpenAIEmbeddings
from langchain_community.vectorstores import FAISS
from langchain_core.documents import Document
from langchain_text_splitters import RecursiveCharacterTextSplitter
client = AzureOpenAI(
api_key="your-azure-openai-key", # API Key
api_version=os.getenv("AZURE_OPENAI_API_VERSION", "2024-12-01-preview"), # 默认使用 2024-02-01
azure_endpoint="https://your-resource-name.openai.azure.com/" # 资源地址
)
# 使用 Azure OpenAI Embeddings
embeddings = AzureOpenAIEmbeddings(
deployment="your-embedding-deployment-name", # 部署名称
model="text-embedding-ada-002", # 模型名称
api_key="your-azure-openai-key", # API Key
azure_endpoint="https://your-resource-name.openai.azure.com/" # 资源地址
)
# 加载文档
text_folder = "RAG files"
documents = []
for filename in os.listdir(text_folder):
if filename.lower().endswith(".txt"):
file_path = os.path.join(text_folder, filename)
loader = TextLoader(file_path)
documents.extend(loader.load())
# 把文档切成小段(每段约1000字,段与段之间有100字重叠)
splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=100)
split_docs = []
for doc in documents:
chunks = splitter.split_text(doc.page_content)
for chunk in chunks:
split_docs.append(Document(page_content=chunk))
documents = split_docs
# 创建向量数据库(存储所有文档的嵌入)
vector_store = FAISS.from_documents(documents, embeddings)
retriever = vector_store.as_retriever()
def main():
print("欢迎使用 RAG 助手。输入 'exit' 退出。
")
while True:
user_input = input("你:").strip()
if user_input.lower() == "exit":
print("退出…")
break
# 找到与问题最相关的文档段落
relevant_docs = retriever.invoke(user_input)
retrieved_context = "
".join([doc.page_content for doc in relevant_docs])
# 告知 AI 只能用这些内容来回答
system_prompt = (
"你是一个乐于助人的助手。"
"只能使用下面的内容来回答问题。"
"如果答案不在内容中,请说你不知道。
"
f"参考内容:
{retrieved_context}"
)
# 准备发送给 AI 的消息
messages = [
{"role": "system", "content": system_prompt},
{"role": "user", "content": user_input}
]
# AI 生成回答
response = client.chat.completions.create(
model="gpt-4",
messages=messages,
)
assistant_message = response.choices[0].message
print(f"
助手:{assistant_message}
")
if __name__ == "__main__":
main()
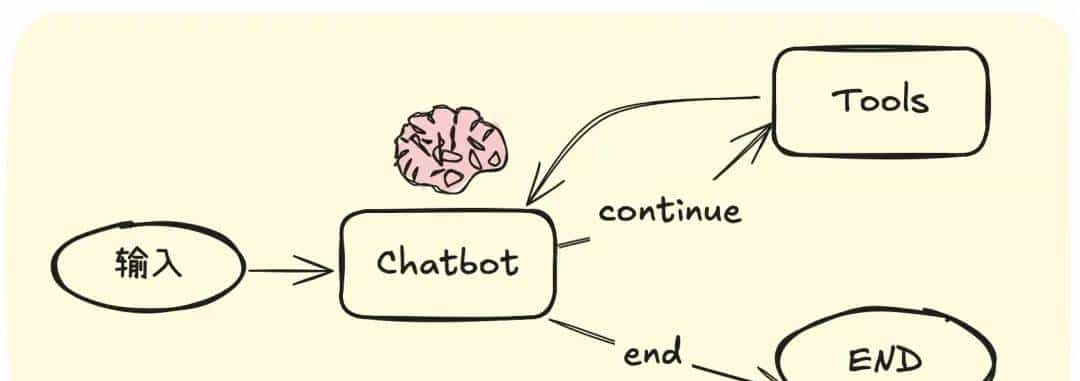
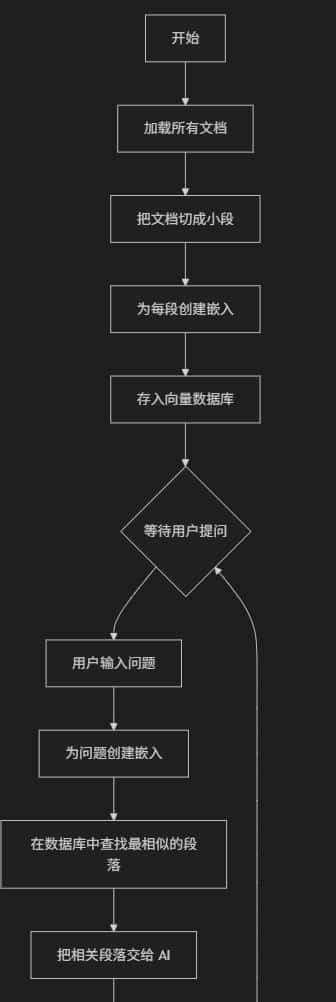
代码工作流程图
使用余弦类似度替代默认方法
默认情况下,代码使用 L2 距离(欧几里得距离)来查找类似内容。如果想改用余弦类似度,需要先对向量进行归一化(把向量长度统一为1):
# 归一化函数:把向量的长度统一为1
import numpy as np
def normalize(vectors):
vectors = np.array(vectors)
norms = np.linalg.norm(vectors, axis=1, keepdims=True)
return vectors / norms
# 归一化所有文档的嵌入
doc_texts = [doc.page_content for doc in documents]
doc_embeddings = embeddings.embed_documents(doc_texts)
doc_embeddings = normalize(doc_embeddings)
# 创建使用点积(内积)的索引
import faiss
dimension = doc_embeddings.shape[1]
index = faiss.IndexFlatIP(dimension) # IP = Inner Product(内积)
index.add(doc_embeddings)
查询时也要归一化:
# 把用户问题的嵌入也归一化
query_embedding = embeddings.embed_query(user_input)
query_embedding = normalize([query_embedding])
# 在索引中搜索最类似的 k=2 个段落
D, I = index.search(query_embedding, k=2)
# D 包含类似度分数,I 包含段落的索引号
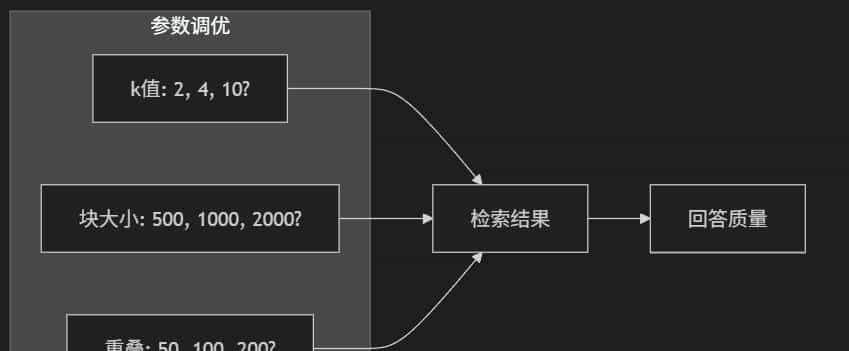
参数的重大性
不同的参数设置会影响 RAG 的效果:
|
参数 |
说明 |
影响 |
|
k 值 |
检索多少个相关段落 |
k 太小可能漏掉重大信息,k 太大可能引入噪音 |
|
chunk_size |
每段文字的大小 |
太小会丢失上下文,太大会不够准确 |
|
chunk_overlap |
段落之间的重叠 |
有助于保持段落间的连贯性 |
|
类似度阈值 |
最低类似度要求 |
过滤掉不够相关的内容 |
总结
RAG 的核心就是三步:
- 嵌入:把文字变成数字,保留语义信息
- 类似度计算:用数学方法找到最相关的内容
- 生成:让 AI 基于找到的内容来回答
就像一个机智的图书管理员,先帮你找到最相关的几本书,然后再根据书中内容回答你的问题。如果大家有任何问题,欢迎评论区留言提问。老白也会在后续的章节中继续发布大模型相关内容,欢迎阅读!
相关阅读:
大模型RAG入门教程:从零开始理解(附含示例)
大模型RAG教程:如何轻松驾驭小文件到西游记巨著
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...